

The field of neural network architectures has witnessed rapid advancements as researchers explore innovative ways to enhance computational efficiency while maintaining or improving model performance. Traditional dense networks rely heavily on computationally expensive matrix operations to encode and store information. This reliance poses challenges when scaling these models for real-world applications that demand extensive knowledge storage and retrieval. Recent research has focused on refining existing architectures to balance computational and memory requirements, providing a pathway for more scalable and energy-efficient AI systems.
The limitations of existing models are their inefficiency in handling simple factual associations, such as relationships between entities or numerical facts. Dense transformer models, while effective in representing complex patterns, require increases in computational resources as their parameter count grows. This inefficiency is problematic when addressing tasks requiring factual accuracy, such as question answering, where the ability to recall specific information is critical. The challenge lies in finding methods that enable models to store and retrieve knowledge without significantly inflating computational demands or memory usage. The need for solutions that scale efficiently with increased parameter size and data demands has become increasingly urgent.
Current techniques, such as mixture-of-experts (MOE) models, have been developed to address some of these challenges. MOE introduces sparsity by activating only a subset of its parameters for a given input, reducing computational overhead compared to fully dense models. However, MOE architectures often fall short in tasks requiring precise factual recall and general knowledge representation. Also, these methods typically require intricate designs and are challenging to implement at scale. Despite this, MOE models have struggled to fully address the growing demands for efficient, scalable architectures, prompting researchers to explore alternative approaches.
To advance the utility of memory layers in AI architectures, researchers from FAIR at Meta focused on scaling and improving their implementation. Initially proposed as a key-value lookup mechanism, memory layers have shown a potential to store and retrieve information efficiently. Meta researchers integrated these memory layers into transformer architectures, replacing feed-forward networks in various configurations. This effort represents a two-order-of-magnitude improvement in memory capacity, with memory parameters scaling up to 128 billion. By revising and optimizing memory layers, the team demonstrated their ability to outperform dense and MOE models in various benchmarks, especially those requiring factual accuracy and knowledge retrieval.
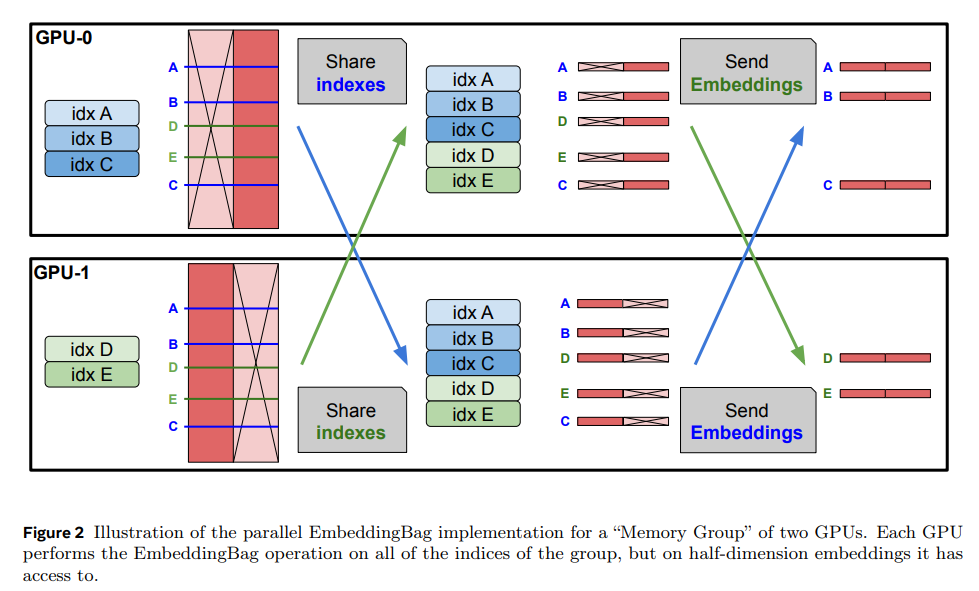
The refined memory layer design incorporates trainable key-value embeddings and leverages sparse activation patterns to enhance efficiency. Product-key lookup, a technique that splits keys into smaller subsets for efficient search, enabled the scaling of memory layers without exponential computational growth. Parallel memory operations across GPUs further streamlined performance, allowing the system to handle millions of keys while maintaining a manageable computational load. In earlier implementations, custom CUDA kernels optimized memory operations, achieving GPU bandwidths close to 3 TB/s compared to less than 400 GB/s.
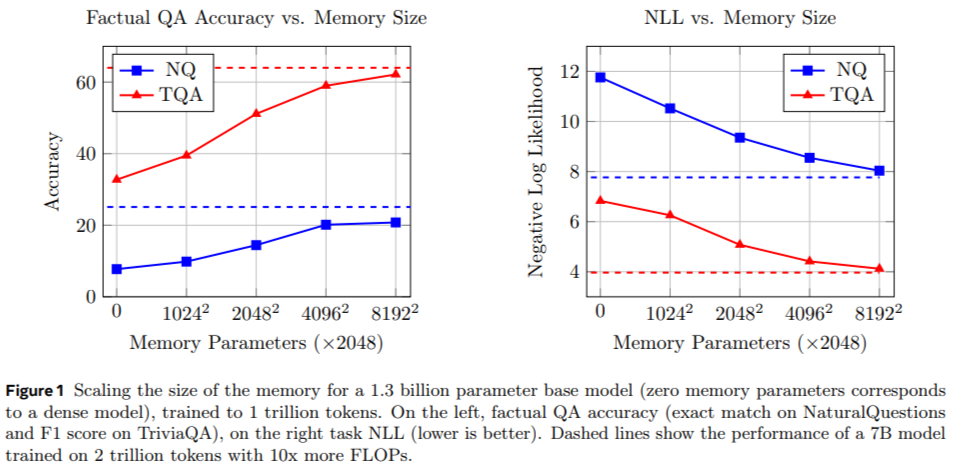
In evaluations, for example, a 1.3 billion-parameter model with memory layers achieved comparable accuracy to dense models with twice the computational requirements. In factual question-answering tasks like NaturalQuestions and TriviaQA, memory-augmented models exhibited over a 100% increase in accuracy. Scaling experiments revealed that memory models with 64 million keys and 128 billion memory parameters approached the performance of the Llama2 7B model, which required more computational resources. Also, memory-augmented models showed faster learning rates, reaching high accuracy with fewer training tokens.
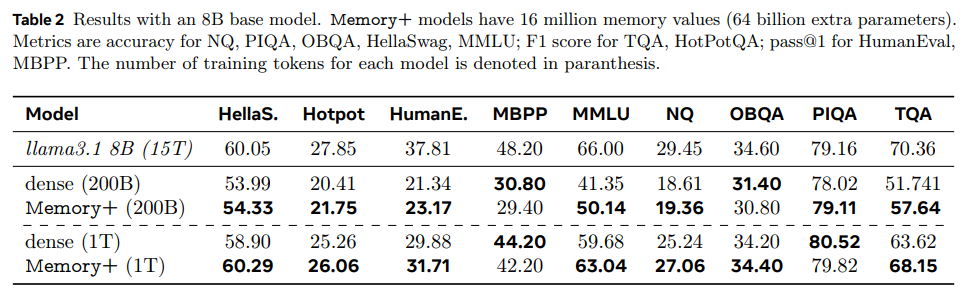
Several takeaways from the research include:
- Memory layers enhanced performance in factual question-answering benchmarks, outperforming dense models with double the computational resources.
- The approach scaled seamlessly across parameter sizes, reaching 128 billion memory parameters and demonstrating consistent accuracy improvements.
- Custom CUDA kernels maximized GPU bandwidth, ensuring efficient implementation of memory operations.
- Memory-augmented models achieved superior results earlier in training, showcasing their ability to learn efficiently with fewer tokens.
- Shared memory pools allowed for a strategic blend of dense and memory layers, optimizing computational and memory efficiency.
In conclusion, Meta FAIR’s research advances the scalability and utility of memory layers in AI models. The study underscores the potential for memory layers to address critical challenges in neural network architectures by refining the implementation and demonstrating their efficiency across various tasks. These findings highlight a promising direction, providing tools to balance computational demands with enhanced knowledge storage capabilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post Can AI Models Scale Knowledge Storage Efficiently? Meta Researchers Advance Memory Layer Capabilities at Scale appeared first on MarkTechPost.