

Visual programming has emerged strongly in computer vision and AI, especially regarding image reasoning. Visual programming enables computers to create executable code that interacts with visual content to offer correct responses. These systems form the backbone of object detection, image captioning, and VQA applications. Its effectiveness stems from the ability to modularize multiple reasoning tasks, but correctness poses a significant problem. In contrast to conventional programming, where logic errors can be detected during syntax checking and debugging, visual programs generate seemingly correct results, but they can be logically incorrect. Improved unit testing methods play a vital role in making them more reliable.
One recurring issue with visual programming is that models give correct answers for wrong reasons. The inability to validate the logic underlying these outputs has severe repercussions, as a well-performing program can suddenly fail unexpectedly when subjected to new data. A recent study of 100 visual programs produced by the CodeLlama-7B model for the GQA dataset showed that only 33% of these programs were correct. On the other hand, 23% needed to be heavily rewritten. Most models are based on statistical correlations rather than actual understanding and are thus susceptible to edge cases. Visual programming lacks systematic testing procedures, bugs tend to go unnoticed, and more robust verification frameworks are needed.
Efforts to improve visual program reliability have primarily focused on training with labeled datasets, but this approach has limitations. Training data can be expensive to annotate and may not cover all potential use cases. Some researchers have explored reinforcement learning strategies prioritizing programs yielding correct answers during training, but these methods do not necessarily ensure logical soundness. Traditional unit testing, widely used in text-based programming, has been adapted to check whether program outputs fall within predefined categories. While these methods provide a level of validation, they do not verify whether the reasoning behind an answer is logically correct. Addressing these limitations requires new solutions that systematically evaluate program behavior.
Researchers at Salesforce AI Research and the University of Pennsylvania have introduced Visual Unit Testing (ViUniT), a framework designed to improve the reliability of visual programs by generating unit tests that evaluate logical correctness. Unlike conventional unit testing techniques, which are mainly used in text-based applications, ViUniT generates test cases in image-answer pairs. These unit tests allow researchers to verify whether a model truly understands the relationships and attributes within an image, rather than relying on statistical shortcuts. The core idea behind this framework is to systematically evaluate visual programs by creating images that serve as test inputs, accompanied by expected answers that the program should generate. This process ensures that models produce correct answers and follow logical steps to reach them.
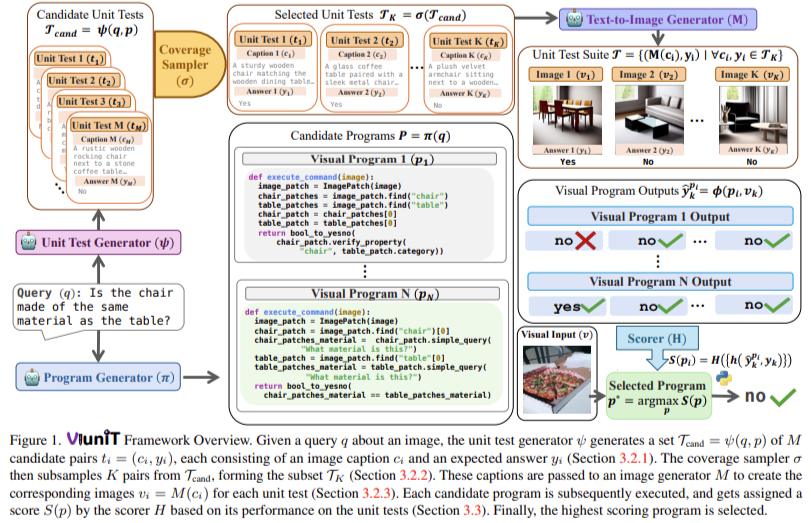
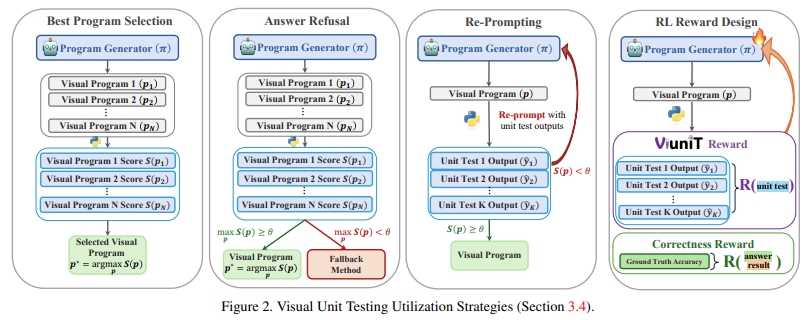
The ViUniT framework leverages LLMs to generate test cases. This process begins with creating candidate image descriptions, which are then converted into synthetic images using state-of-the-art text-to-image generation models. To maximize the effectiveness of unit testing, ViUniT incorporates an optimization criterion that selects image descriptions that provide the best test coverage for different scenarios. The system then executes the visual program on these test images, comparing the program’s response to the expected answer. A scoring function is used to assess how well the program performs on these tests, and programs that fail the tests can either be refined or discarded. This structured approach ensures that unit tests are comprehensive and can identify a wide range of potential errors. The framework also introduces four key applications for visual unit tests: best program selection, answer refusal, re-prompting, and reinforcement learning-based reward design. These applications allow researchers to improve model reliability by selecting the best-performing programs, refusing to generate answers when confidence is low, refining programs through iterative prompts, and training models using unit-test-driven reinforcement learning.
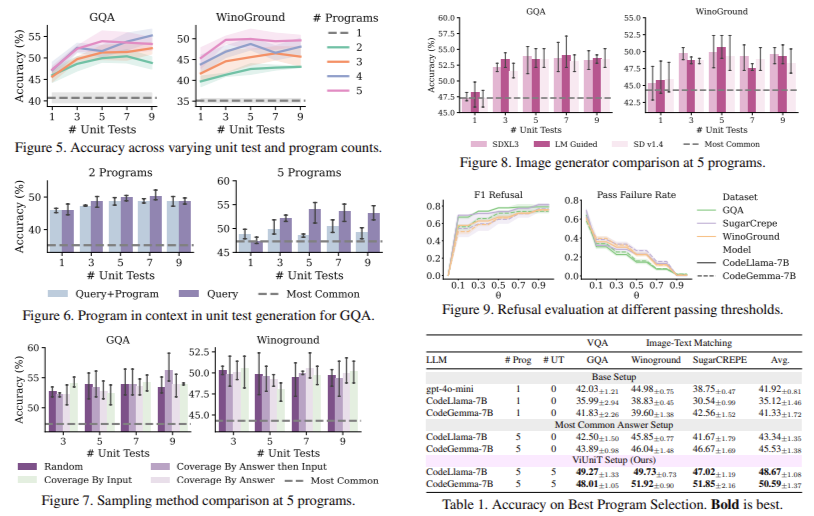
To evaluate ViUniT, researchers conducted extensive experiments on three datasets, GQA, SugarCREPE, and Winoground, which are commonly used benchmarks for assessing visual reasoning and image-text matching. The results demonstrated that ViUniT significantly enhances model performance. Specifically, it improved accuracy by 11.4% on average across all datasets. The framework also allowed open-source models with 7 billion parameters to outperform proprietary models like GPT-4o-mini by 7.7% on average. Also, ViUniT successfully reduced the number of programs that were correct for incorrect reasons by 40%. The reinforcement learning-based reward design implemented within ViUniT proved highly effective, outperforming traditional correctness-based reward strategies by 1.3%. This improvement indicates that unit testing is useful for detecting errors and actively refining and improving model performance. Introducing answer refusal strategies also contributed to reliability, ensuring that models do not provide misleading responses with low confidence.
Several key takeaways from the research include:
- Only 33% of tested visual programs in GQA were fully correct, while 23% required extensive rewriting due to logical flaws.
- ViUniT reduced logically flawed programs by 40%, ensuring that models rely on sound reasoning rather than statistical shortcuts.
- The framework improved model accuracy by 11.4% on average across three datasets.
- ViUniT enabled 7B open-source models to outperform GPT-4o-mini by 7.7%.
- The framework introduced four novel applications—best program selection, answer refusal, re-prompting, and reinforcement learning reward design.
- ViUniT-based re-prompting improved performance by 7.5 percentage points compared to error-based re-prompting.
- The reinforcement learning strategy used in ViUniT outperformed correctness-based reward strategies by 1.3%.
- The system successfully identified when programs were unreliable, improving answer refusal strategies and reducing false confidence.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Salesforce AI Proposes ViUniT (Visual Unit Testing): An AI Framework to Improve the Reliability of Visual Programs by Automatically Generating Unit Tests by Leveraging LLMs and Diffusion Models appeared first on MarkTechPost.
Leave a Reply