

Large Language Models (LLMs) are essential in fields that require contextual understanding and decision-making. However, their development and deployment come with substantial computational costs, which limits their scalability and accessibility. Researchers have optimized LLMs to improve efficiency, particularly fine-tuning processes, without sacrificing reasoning capabilities or accuracy. This has led to exploring parameter-efficient training methods that maintain performance while reducing resource consumption.
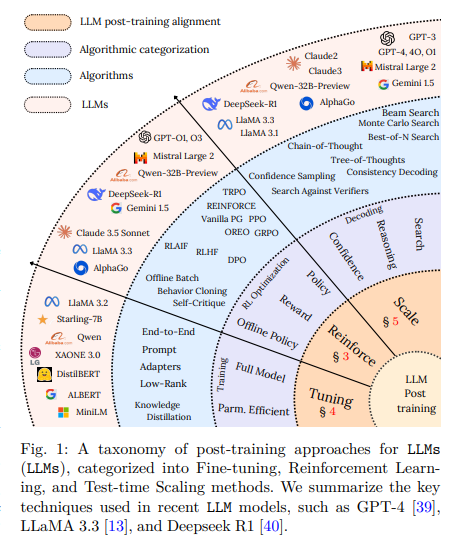
One of the critical challenges faced in the field is the excessive cost of training and fine-tuning LLMs. These models require massive datasets and extensive computational power, making them impractical for many applications. Moreover, traditional fine-tuning methods lead to overfitting and require significant memory usage, making them less adaptable to new domains. Another problem is the inability of LLMs to handle multi-step logical reasoning effectively. While they perform well on straightforward tasks, they often struggle with math problems, complex decision-making, and maintaining coherence in multi-turn conversations. To make LLMs more practical and scalable, it is necessary to develop methods that reduce the computational footprint while enhancing their reasoning capabilities.
Previous approaches to improving LLM efficiency have relied on instruction fine-tuning, reinforcement learning, and model distillation. Instruction fine-tuning enables models to understand better and respond to user prompts, while reinforcement learning helps refine decision-making processes. However, these methods require labeled datasets that are expensive to obtain. Model distillation, which transfers knowledge from larger models to smaller ones, has been another approach, but it often results in a loss of reasoning ability. Researchers have also experimented with quantization techniques and pruning strategies to reduce the number of active parameters, but these methods have had limited success in maintaining model accuracy.

A research team from DeepSeek AI introduced a novel parameter-efficient fine-tuning (PEFT) framework that optimizes LLMs for better reasoning and lower computational costs. The framework integrates Low-Rank Adaptation (LoRA), Quantized LoRA (QLoRA), structured pruning, and novel test-time scaling methods to improve inference efficiency. Instead of training entire models, LoRA and QLoRA inject trainable low-rank matrices into specific layers, reducing the number of active parameters while preserving performance. Structured pruning further eliminates unnecessary computations by removing redundant model weights. Also, the researchers incorporated test-time scaling techniques, including Beam Search, Best-of-N Sampling, and Monte Carlo Tree Search (MCTS), to enhance multi-step reasoning without requiring retraining. This approach ensures that LLMs dynamically allocate computational power based on task complexity, making them significantly more efficient.
The proposed method refines LLM reasoning by integrating Tree-of-Thought (ToT) and Self-Consistency Decoding. The ToT approach structures logical steps into a tree-like format, allowing the model to explore multiple reasoning paths before selecting the best answer. This prevents the model from prematurely committing to a single reasoning path, often leading to errors. Self-Consistency Decoding further enhances accuracy by generating multiple responses and selecting the most frequently occurring correct answer. Further, the framework employs distillation-based learning, allowing smaller models to inherit reasoning abilities from larger ones without extensive computation. By combining these techniques, the researchers have achieved high efficiency without compromising performance. The methodology ensures that models trained with less than half the computational resources of traditional methods perform at similar or higher levels on complex reasoning tasks.

Extensive evaluations demonstrated that test-time scaling enables models to perform comparably to those 14× larger on easy-to-intermediate tasks while reducing inference costs by 4× FLOPs. LoRA and QLoRA contribute to memory-efficient training by integrating 4-bit quantization with low-rank adaptation, enabling fine-tuning on consumer GPUs. BitsAndBytes provides 8-bit optimizers to optimize memory usage while maintaining model performance. Tree-of-thought reasoning enhances structured multi-step problem-solving, improving decision-making accuracy in complex tasks. At the same time, Monte Carlo Tree Search refines response selection in multi-step reasoning scenarios, particularly in scientific Q&A tasks. These findings highlight the potential of parameter-efficient fine-tuning to improve LLM efficiency without sacrificing reasoning capabilities.
This research provides a practical and scalable solution for improving LLMs while reducing computational demands. The framework ensures that models achieve high performance without excessive resources by combining parameter-efficient fine-tuning, test-time scaling, and memory-efficient optimizations. The findings suggest that future developments should balance model size with reasoning efficiency, enabling broader accessibility of LLM technology. With companies and institutions seeking cost-effective AI solutions, this research sets a foundation for efficient and scalable LLM deployment.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post This AI Paper Introduces a Parameter-Efficient Fine-Tuning Framework: LoRA, QLoRA, and Test-Time Scaling for Optimized LLM Performance appeared first on MarkTechPost.
Leave a Reply