

Deep learning models, having revolutionized areas of computer vision and natural language processing, become less efficient as they increase in complexity and are bound more by memory bandwidth than pure processing power. The latest GPUs struggle with tremendous bandwidth limitations as they are constantly needed to move data between varying levels of memory. This process slows computations and increases energy consumption. The challenge is to develop methods that minimize unnecessary data transfers while maximizing computational throughput improving training and inference efficiency.
A primary issue in deep learning computation is optimizing data movement within GPU architectures. Although GPUs provide immense processing power, their performance is often restricted by the bandwidth required for memory transfers rather than their computing capabilities. Current deep learning frameworks struggle to address this inefficiency, leading to slow model execution and high energy costs. FlashAttention has previously demonstrated performance improvements by reducing redundant data movement, but existing methods rely heavily on manual optimizations. The absence of an automated, structured approach to GPU workload optimization remains a major hurdle in the field.
Existing techniques such as FlashAttention, grouped query attention, KV-caching, and quantization aim to reduce memory transfer costs while maintaining computational efficiency. FlashAttention, for example, reduces overhead by performing key operations within local memory, eliminating unnecessary intermediate data transfers. However, these methods have traditionally required manual optimization tailored to specific hardware. Some automated approaches, such as Triton, exist but have not yet reached the performance levels of manually tuned solutions. The demand for a systematic and structured approach to developing memory-efficient deep learning algorithms remains unfulfilled.
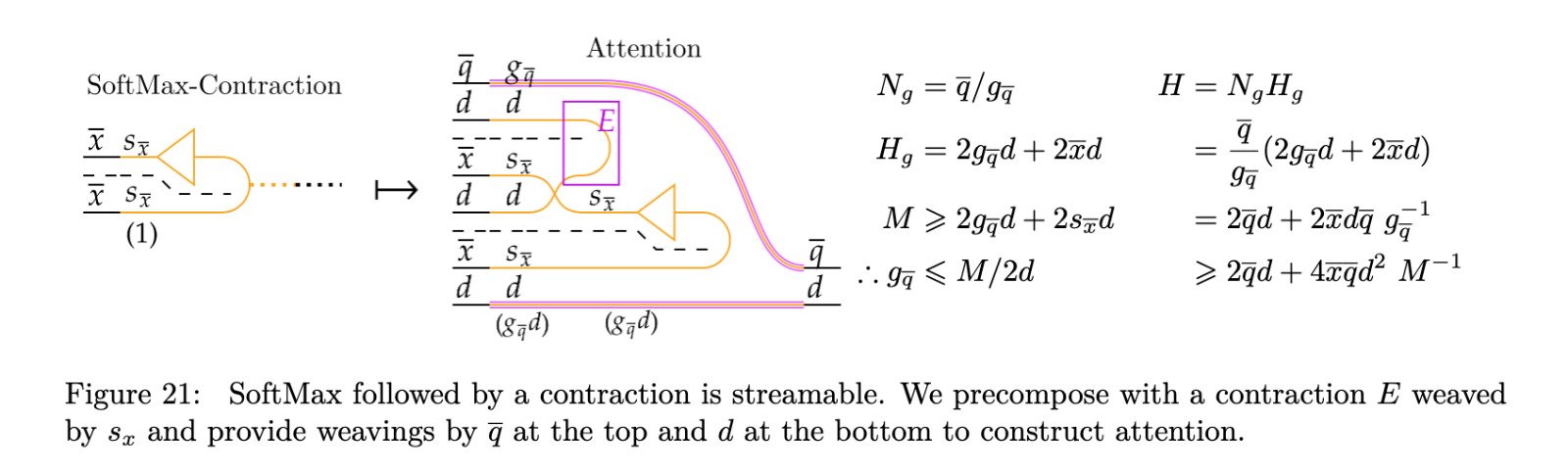
University College London & MIT researchers introduced a diagrammatic approach to optimize deep learning computations. Their method extends Neural Circuit Diagrams to account for GPU resource usage and hierarchical memory distribution. By visualizing computational steps, this technique enables systematic derivation of GPU-aware optimizations. The researchers propose a framework that simplifies algorithmic design by providing a structured methodology for performance modeling. The approach focuses on minimizing data movement, optimizing execution strategies, and leveraging hardware features to achieve high computational efficiency.
The proposed methodology employs a hierarchical diagramming system that models data transfers across different levels of GPU memory. This framework enables researchers to break down complex algorithms into structured visual representations, allowing for the identification of redundant data movements. Researchers can derive streaming and tiling strategies that maximize throughput by relabeling and restructuring computations. The diagrammatic approach also considers quantization and multi-level memory structures, making it applicable across different GPU architectures. The framework provides a scientific foundation for GPU optimization beyond ad-hoc performance tuning.
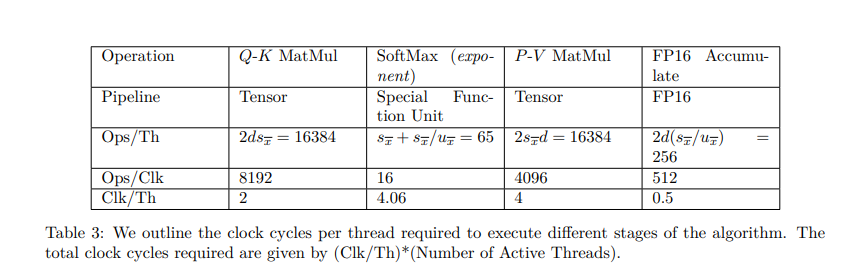
The research demonstrates that the diagrammatic approach significantly enhances performance by reducing memory transfer inefficiencies. FlashAttention-3, optimized using this method, achieves a 75% improvement in forward speed on newer hardware. The study shows that utilizing structured diagrams for GPU-aware optimizations enables high efficiency, with empirical results confirming the approach’s effectiveness. Specifically, FP16 FlashAttention-3 reaches 75% utilization of its maximum theoretical performance, while FP8 achieves 60%. These findings highlight the potential of diagram-based optimization for improving memory efficiency and computational throughput in deep learning.
This study introduces a structured framework for deep learning optimization, focusing on minimizing memory transfer overhead while enhancing computational performance. The proposed method provides a systematic alternative to traditional manual optimization approaches. Researchers can better understand hardware constraints and develop efficient algorithms by leveraging diagrammatic modeling. The findings suggest that structured GPU optimization can significantly improve deep learning efficiency, paving the way for more scalable and high-performance AI models in real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.


 It’s operated using an easy-to-use CLI
It’s operated using an easy-to-use CLI  and native client SDKs in Python and TypeScript
and native client SDKs in Python and TypeScript  .
.The post This AI Paper from MIT and UCL Introduces a Diagrammatic Approach for GPU-Aware Deep Learning Optimization appeared first on MarkTechPost.
Leave a Reply